
2023年12月15日,2023首届服务韧性工程(SRE)论坛在杭州成功举办。本次会议由中国信息通信研究院·稳定性保障实验室、中国移动通信集团浙江有限公司联合主办,中关村人才协会、SRE专委会、雅菲奥朗、广通优云承办。会议邀请了来自通信、金融、医疗、制造等行业100余位SRE领域专业人士,共同探讨服务韧性工程的最新发展趋势和创新实践。老娘舅餐饮股份有限公司数据与技术中台负责人沈钊带来《携手移动云共建自动化运维能力,提升系统稳定性》主题演讲。

老娘舅餐饮股份有限公司数据与技术中台负责人 沈钊
老娘舅餐饮股份有限公司数据与技术中台负责人沈钊,进行《携手移动云共建自动化运维能力,提升系统稳定性》的演讲。他介绍了浙江移动自23年初与老娘舅合作,支撑老娘舅将多个业务系统迁移至移动云,并与移动云携手共建自动化运维能力,着重介绍了如何提高系统稳定性的方式。同时通过案例,阐述了自动化运维对系统效率和稳定性的积极影响。
以下为演讲实录:
老娘舅是一家深耕长三角的老牌餐饮企业,400家门店遍布江浙沪皖,老娘舅的米饭类产品可以说是全行业中的佼佼者。“追求101%的顾客满意”不仅仅是老娘舅的口号,更是实际行动。老娘舅的管理者们在餐厅的各个环节力求做到完美,再结合现代餐厅的全信息化营业模式,这也给信息系统的稳定带来了新的课题。

公司层面能不能做到服务器、云服务、各系统的100%稳定?
答案是肯定能,但是为了这个目标老娘舅要付出极大的努力,在运维层面我把整个过程分为3个阶段,原始人、现代人、未来人,原始人用人的方式去做运维,现代人用工具去做运维,未来人采用自动化运维方式。
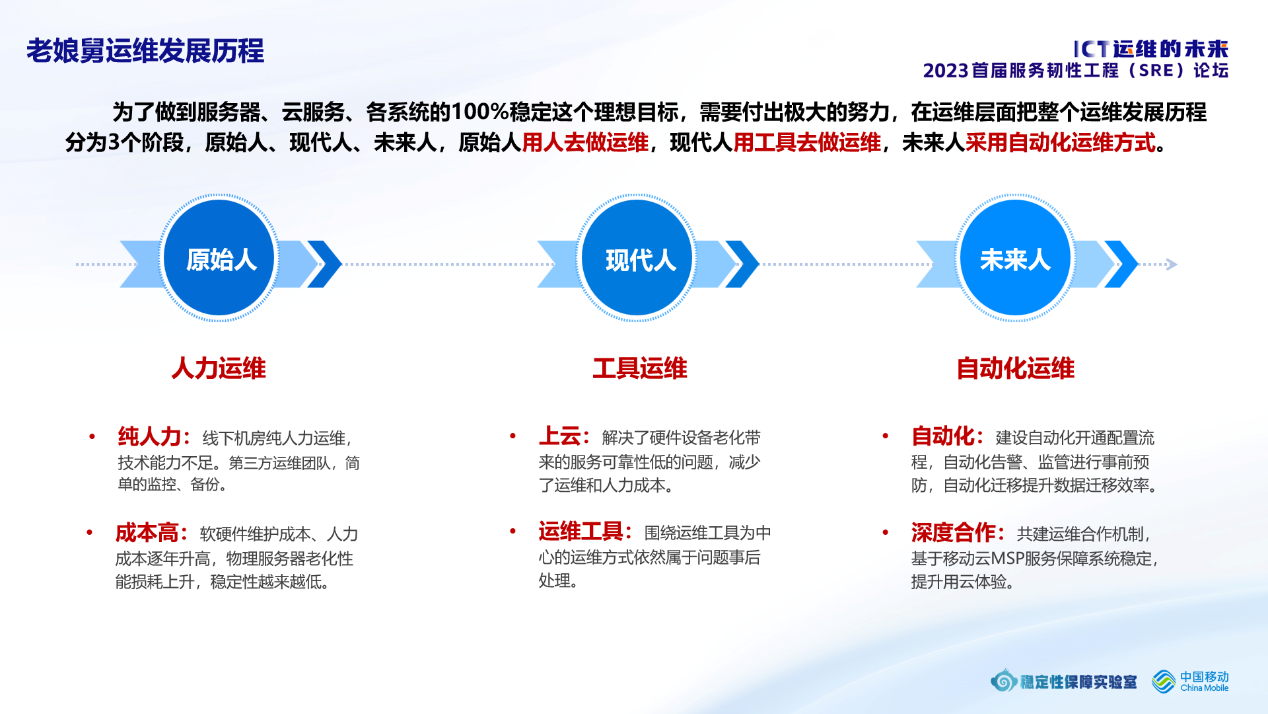
原始人阶段:早期老娘舅的服务器在线下机房中,运维工作全部由老娘舅的工程师负责。工程师的水平有限,往往只能做到事后解决,甚至于有些复杂的问题,事后都不能彻底解决。后来外包了第三方运维团队,第三方运维团队也只能做到一些简单的监控、备份,还原数据到是有了保障,但是服务器本身的稳定性随着年限越来越多问题、运维的硬件、软件、人工等成本蹭蹭蹭的往上涨。
现代人阶段:到现代人阶段的标志性事件就是上云,服务器上云首先解决了硬件设备老化带来的不确定性问题,然后也减少了运维团队的工作量变相减少了运维成本。上云之后改变了原本的运维方式,从以人为运维中心的运维方式改进为以运维工具为中心的运维方式,以前运维人员主要忙活在机房里,现在运维人员忙活在电脑前。本质其实并没有变化,总结来说都是事后解决问题。
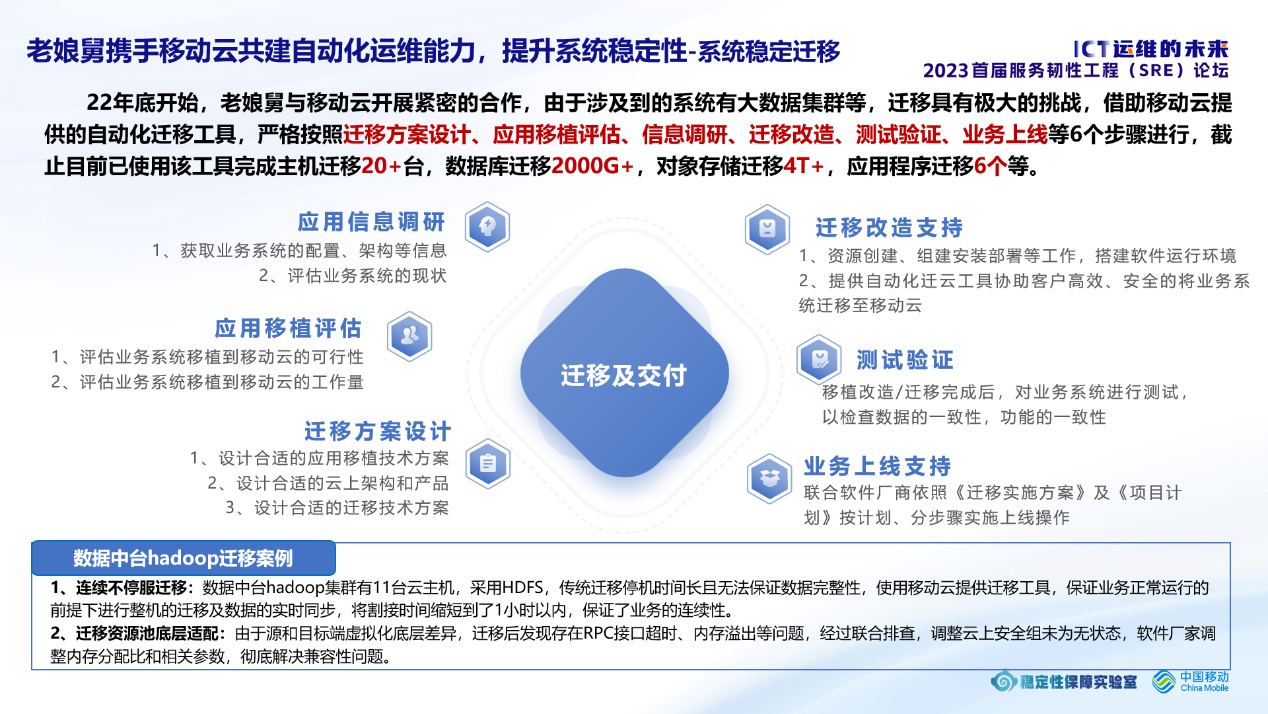
未来人阶段:今年老娘舅做了一个非常重大的改革,就是将服务器迁移到移动云上,选择移动云主要看中的就是移动云的运维能力和配合度,以前云服务厂商更多的是幕后工作,只要服务器、网络没问题,就没事了。甚至于出现问题,只要客户不够专业就把问题推向资源不够用,既推卸了责任,又增加了营收,已经变成创收的另一个方式。移动云的运维团队和老娘舅紧密协作形成了一些自动化运维经验。
01.事前预防:
我主张运维工作应该是事前预防为先,事后总结为二,事中处理为末,以前往往是重视事中处理,以最快的方式解决,再做事后总结,很多问题还是会不断的重复发生,往往事前预防是做的最差的,要想做好事前预防不得不从组织管理过程入手去改进。

(1)自动化开通配置:开通外网严格流程化,使用跳板机访问内网服务
通过对外网开通的限制很大程度上限制了外部对服务器漏洞的攻击,避免了很多的运维工作。修复漏洞是服务器运维过程中非常费力还容易出现新故障的事情,不仅仅是运维团队不愿意做,服务商也不愿意做。所以老娘舅和移动云的老师制订了共同参与的流程,保证每个外网开通都是必须的,限制范围的,甚至于有时效性的。访问内网的服务比如数据库则使用跳板机。这里不得不表扬一下移动云的跳板机,已经做到和真机的远程桌面几乎一样的操作体验,通常老娘舅两个显示器或者两个桌面切换非常方便。这也让很多小伙伴放下了对跳板机的不便利的反对。
(2)自动化告警:服务器告警智能化
内存超了,cpu跑满了,带宽跑满了,磁盘突然满了,这些信息早期老娘舅往往是事后分析才发现的,前几年是告警有的,但是“告警太多了没发现那个最重要的;告警只能在云平 台上看,我又不可能24小时看着云平台的网页;告警的时候正好是睡觉的时候,不知道这事情。”这都是以前运维人员告诉老娘舅的理由。
今年老娘舅和移动云的老师一起做了一个告警中心,首先将告警分重要性,设定阈值,一般的告警就在网页上展示,由移动云的老师负责关注,重要的告警通过告警中心以文字的方式告警到该服务器的管理员、服务器上应用程序的开发公司,严重的告警通过告警中心以电话的方式通知到该服务器的管理员、服务器上应用程序的开发公司,老娘舅在电话告警中设计了,排班和升级机制,我对这个电话告警的理解,就是大人物办公桌上的那个没有拨号盘的“红色电话”。而且我在这个电话告警的后面设计了一个反馈流程,一旦触发了电话告警,就会要求相关负责人填写处理结果,并上升到信息部负责人的层面。让所有的人都知道这个电话告警是最重要的事情。
(3)自动化监管:自动化监管服务器的访问权限和用户权限,以确保数据安全
以前老娘舅堡垒机账号、管理员账号开通流程浮于表面,甚至于出现过人员离职了很久账号一直没有收回的情况。
现在老娘舅对接移动云开发了一个自动化巡查中心,主要是可以透视每个账号的权限范围、对应人员状态、操作记录,这样将有风险的操作、人员及时标记出来,及时纠正。下一步还将会对重要应用程序做类似的监管,比如数据库的敏感动作、应用程序的异常发布等。避免一些人为的意外的发生,保障了服务器的稳定,也救人于不幸。
(4)自动化云产品:云产品的使用一直是云服务商优于线下机房的一个重要优势
传统的云服务厂商的云服务产品不适合于现在多云策略的实施,迁云简直是一场灾难,移动云的自动化迁云工具,已经帮助我成功迁移了一整套数据中台、各种几百G的数据库、一整套BI平台、各种应用系统更是不在话下。这种工具大大降低了服务器的迁移难度,提高了迁移的成功率,也打消了服务商对于迁移的抵触情绪。
(5)全员培训明确责任边界落实考核措施
传统的服务器运维是由运维工程师负责,运维工程师驱动程序员、服务商去进行运维工作,往往是推不动的。老娘舅和移动云的老师一起组织全员培训,除了运维人员、程序员和厂商的服务人员都要参与,根据所负责的范围进行培训和考核。并制定了运维工程师、公司内技术人员、厂商人员的责任划分和绩效考核,对发生的生产事故责任到人,考核到人。
02.事后总结:
生产事故已经发生了,当时解决了,是不是事情就结束了?以前确实就是这样的。“服务器重启了一下;内存加过了;日志清理了……”这就是以前的事后总结。老娘舅结合公司“亮灯机制”,由结合和移动云共创的告警中心,对电话告警的每一条内容都要求,进行5W反馈,核心目的是找到事故发生的真正的症结。“服务为什么挂掉了?内存之前告警过为什么没有处理?硬盘空间已经连续5天高于90%为什么没有响应”通过这样的一个一个深入人心的问题,将发生的生产事故总结后汇总到事前预防,精进事前预防的内容,更新培训教材,进一步将事故杜绝于事前预防中。形成一个管理闭环。

03.事中处理:
每个系统有一个独立的事故处理流程,运维工程师明确知道对接的技术人员和服务商的联系方式,对事故处理过程的细节进行全程掌握,并编写事故处理报告。对于没有找到明确原因的事故,建立预估的监控机制,添加到事前预防机制中。对已经发生的事故在全域范围内进行排查并添加事前预防机制,以防止同类问题在其他服务器上重现。移动云老师作为老娘舅运维工程师的坚强后盾,为老娘舅快速定位问题,快速解决问题提供帮助,从原来1方定性事故,到现在2方定性事故,更好的避免了推卸责任,也更好的对事故的真实原因进行定位和处理。
综上所述,2024年,老娘舅计划联合移动云研发三个运维中心(监控告警中心、补丁外壳中心、密码管理中心),全面提升运维智能化、合规性,确保系统稳定可靠。用运维手段保证系统101%的稳定,用服务追求101%的顾客满意。
关注我们:

