引言
本期分享主题是GitOps 实践之渐进式交付,本期分享内容为GitOps 与渐进式交付、k8s 内置机制浅析以及使用 ArgoCD/CODING 实施渐进式交付。
一、GitOps与渐进式交付
(1)Release Engineering Principles
The basic principles of release engineering are as follows:
发布工程的基本原则如下:
Reproducible builds 可复现的构建
The build system should be able to take the build inputs(source codeassetsand so on)and produce repeatable artifacts.The code built from the same inputs last week should produce the same output this week.
构建系统应该能够接受构建输入(源代码、资源等)并产生可重复的工件。从上周相同的输入构建的代码应该产生本周相同的输出。
Automated builds 自动化构建
Once code is checked inautomation should produce build artifacts and upload them to a storage system.
一旦代码被检入,自动化应该产生构建工件并将其上传到存储系统。
Automated tests 自动化测试
Once the automated build system builds artifactsa test suite of some kind should ensure they function.
一旦自动化构建系统构建了工件,一种测试套件应该确保它们的功能。
Automated deployments 自动化部署
Deployments should be performed by computers not humans.
部署应该由计算机执行,而不是人类。
Small deployments 小规模部署
Build artifacts should contain small,self-contained changes.
构建工件应该包含小而独立的更改。
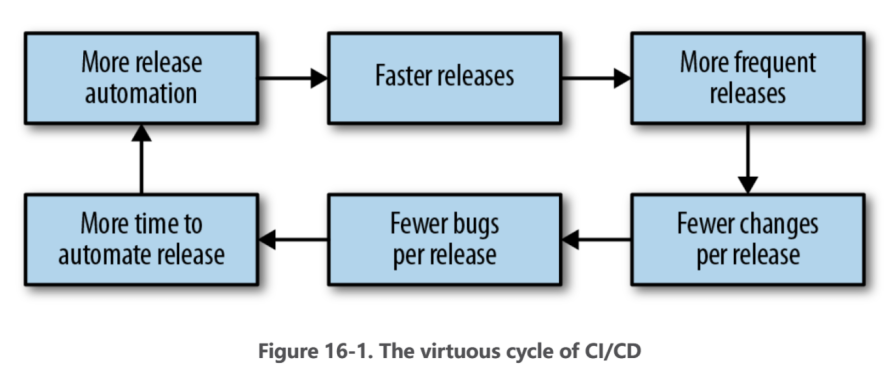
Cl/CD coupled with release automation can deliver continuous improvements to the development cycle, as shown in Figure 16-1.When releases are automated,you can release more often.For software with a nontrivial rate of chanae.releasina more often means fewer chanaes are bunded in anv aiven release artifact.Smaller, self contained release artifacts make it cheaper and easier to roll back any given release artifact in the event of a bug Ouicker release cadences mean that bua fixes reach users faster.
CI/CD与发布自动化相结合可以在开发周期中实现持续改进,如图16-1所示。当发布被自动化时,您可以更频繁地进行发布。对于具有较高变更率的软件来说,更频繁的发布意味着在任何给定的发布工件中捆绑的变更更少。更小、自包含的发布工件使得在出现错误时回滚任何给定的发布工件更加廉价和容易。更快的发布节奏意味着错误修复能够更快地到达用户手中。
(2)Balancing Release Velocity and Reliability
Release velocity(hereafter called“shippina”)and reliabillity are often treated as opposina aoalsThe business wants to ship new features and product improvements as quickly as possible with 100% reliability! While that goal is not achievable(as 100% is never the right target for reliability; see Implementing SLOs)it is possible to ship as quickly as possible while meeting specific reliability goals for a given product.
发布速度(以下简称为“发布”)和可靠性通常被视为相反的目标。企业希望以尽可能快的速度发布新功能和产品改进,同时保持100%的可靠性!虽然这个目标是不可实现的(因为100%从未是可靠性的正确目标;参见实施SLOs),但可以在满足给定产品的特定可靠性目标的同时尽可能快地进行发布。
The first step toward this goal is understanding the impact of shipping on software reliability In Google's experience,a majority of incidents are triggered by binary or configuration pushes(see Results of Postmortem Analysis). Many kinds of software changes can result in a system failure-for examplechanges in the behavior of an underlying componentchanges in the behavior of a dependency(such as an API),or a change in configuration like DNS.
实现这个目标的第一步是了解发布对软件可靠性的影响。根据Google的经验,大多数事故是由二进制或配置推送引发的(参见事故调查分析结果)。许多种软件变更可能导致系统故障,例如底层组件行为的变更、依赖项(如API)行为的变更,或者DNS等配置的更改。
Despite the risk inherent in making changes to softwarethese changes-bug fixessecurity patches, and new features-are necessary for the business to succeed.Instead of advocating against change you can use the concept of SLOs and error budgets to measure the impact of releases on your reliabilityYour goal should be to ship software as quickly as possible while meeting the reliability targets your users expect.The following section discusses how you can use a canary process to achieve these goals.
尽管对软件进行更改存在风险,但这些更改(例如错误修复、安全补丁和新功能)对企业的成功是必要的。您可以利用SLOS和错误预算的概念来衡量发布对可靠性的影响,而不是反对变更。您的目标应该是在满足用户期望的可靠性目标的同时尽快发布软件。下一节将讨论如何使用金丝雀流程来实现这些目标。
(3)GitOps 的诞生
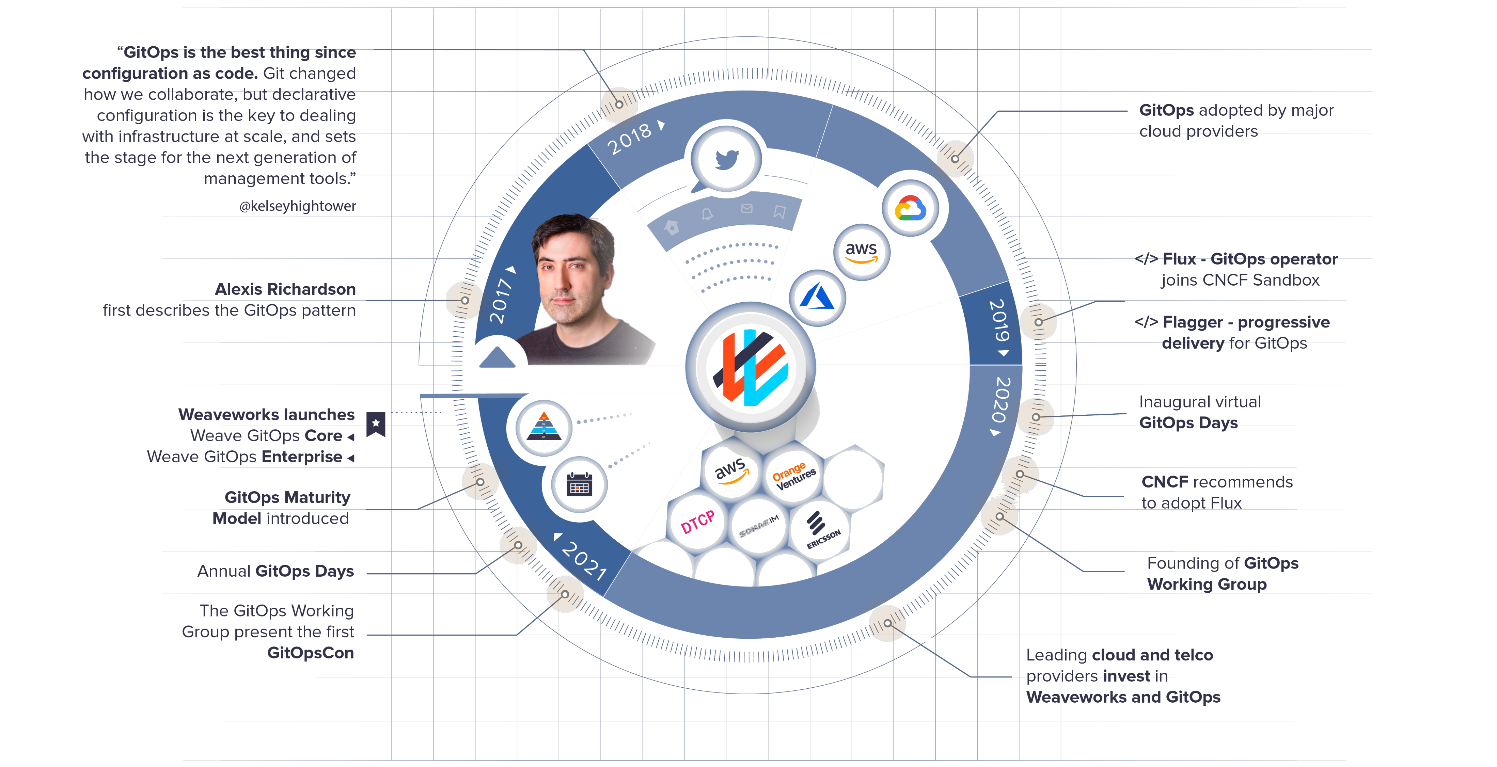
(4)GitOps 的实践
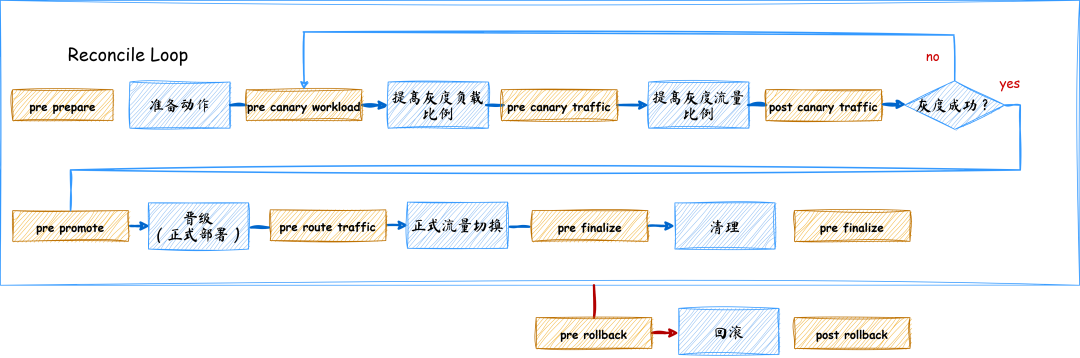
(5)常见部署策略
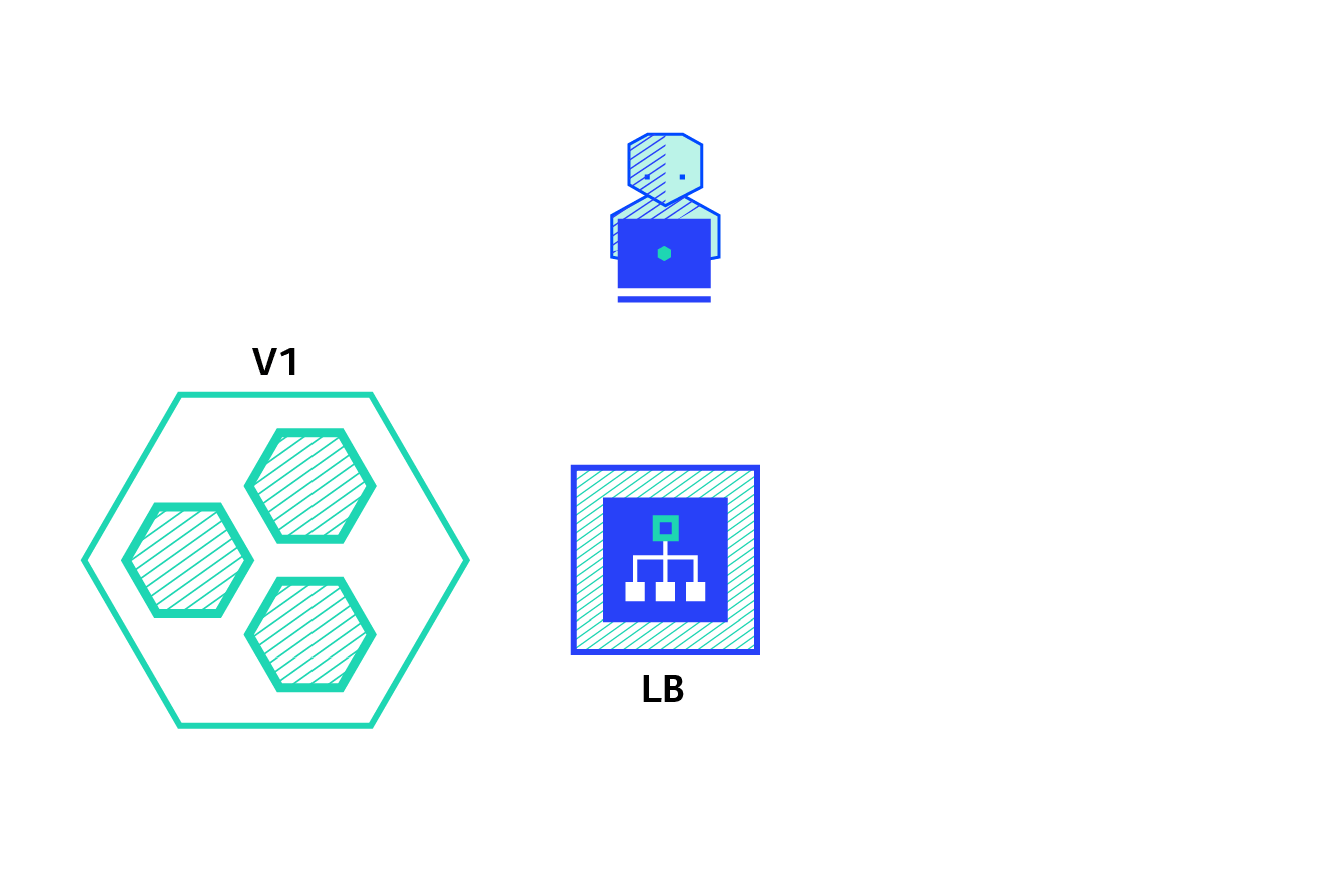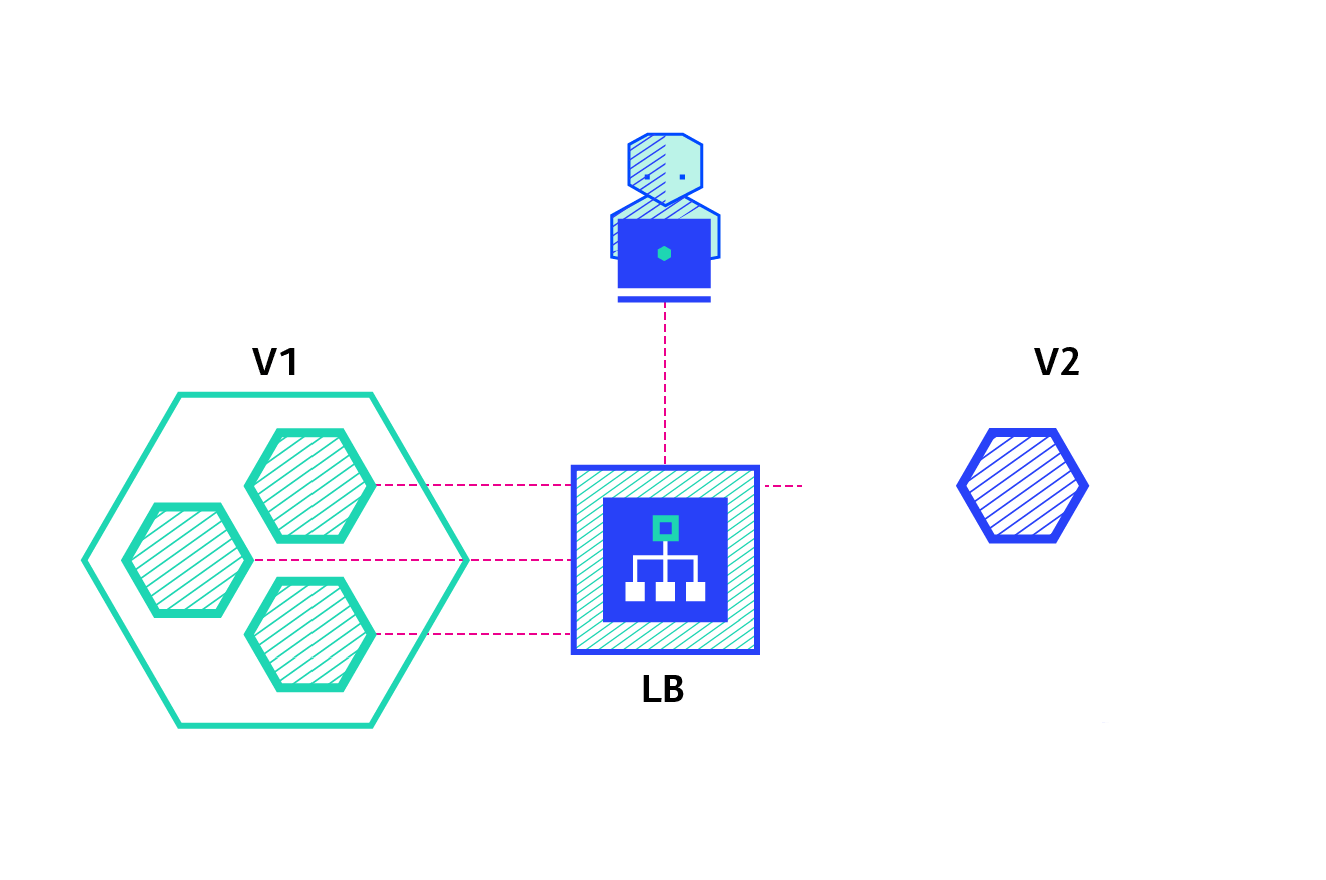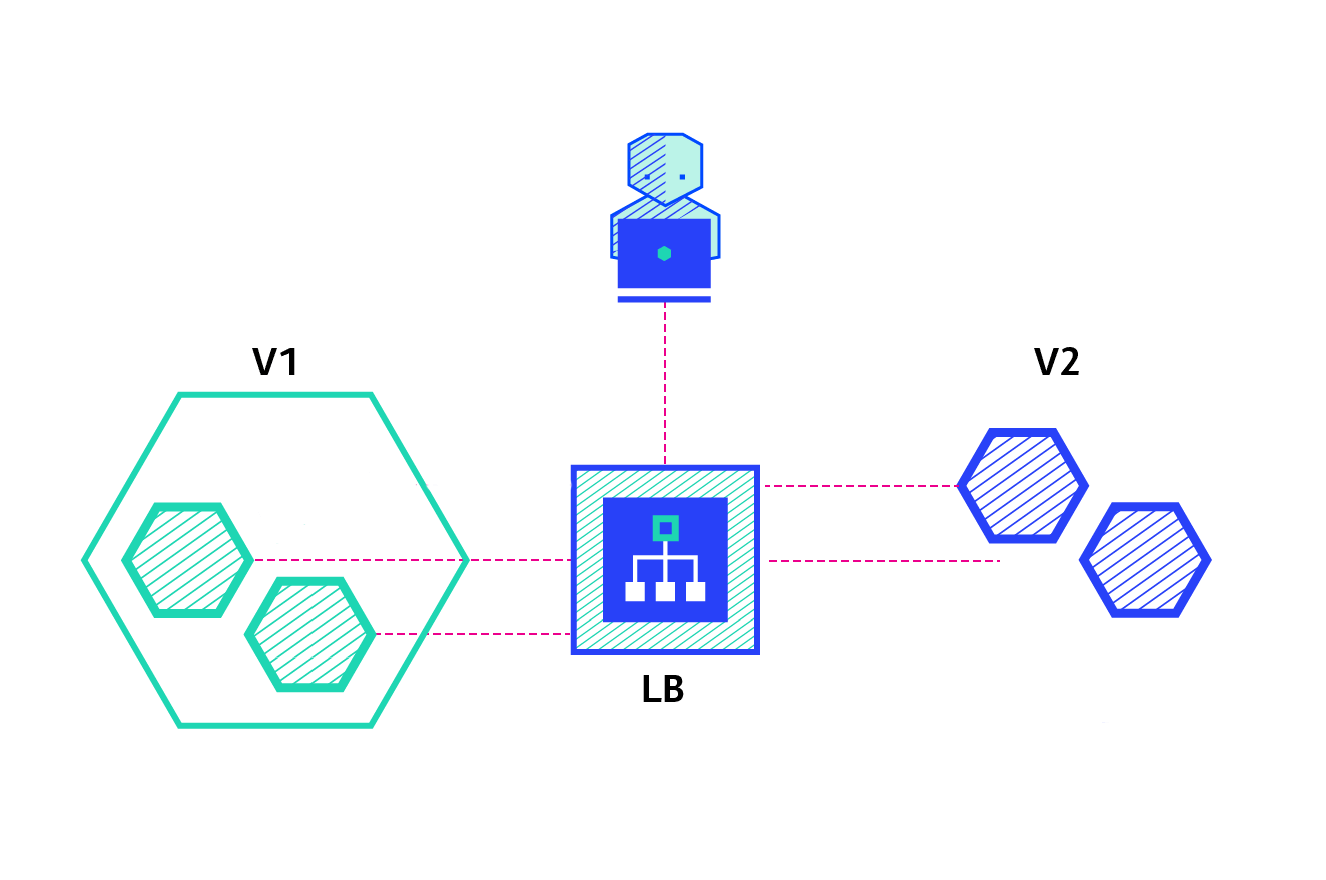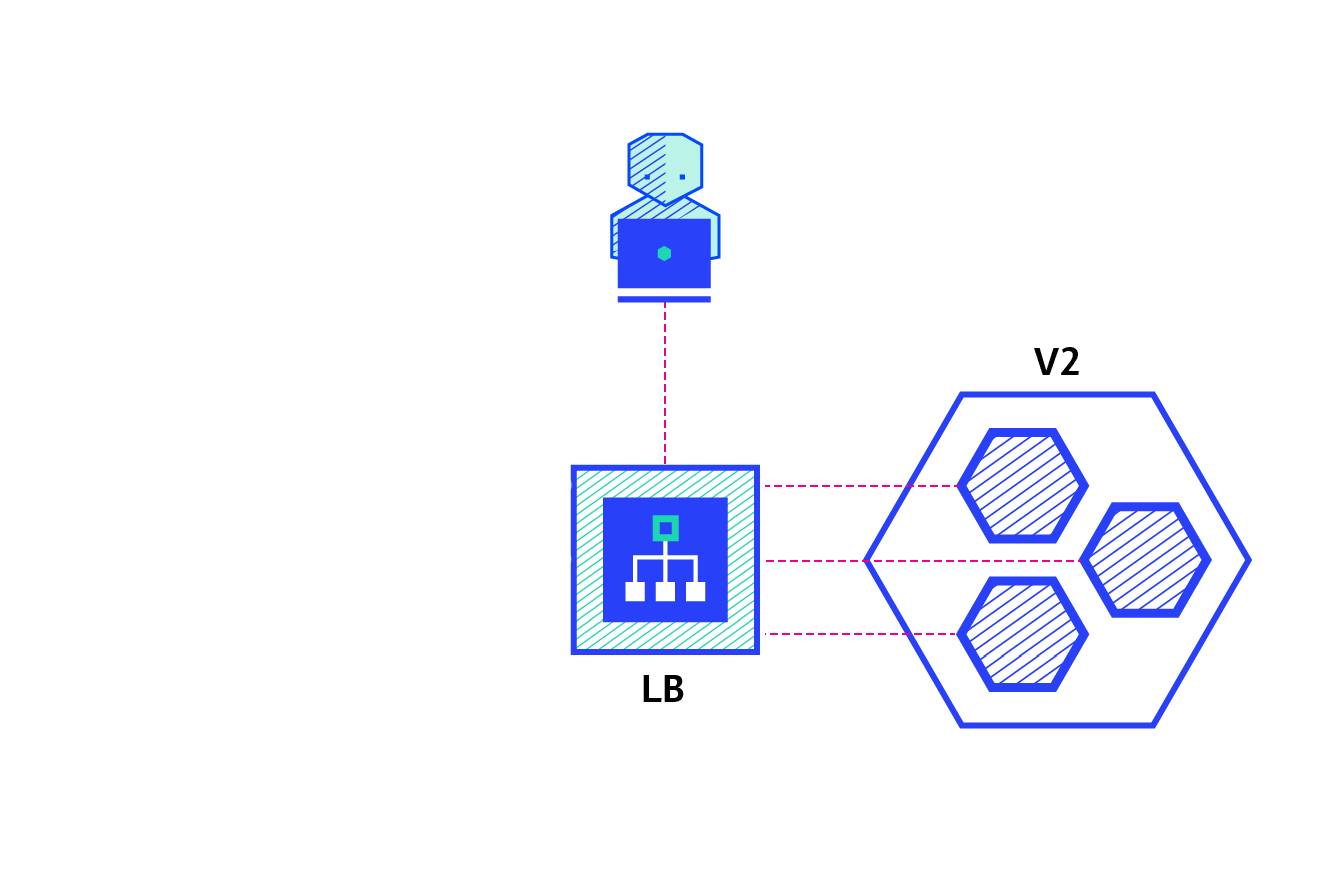

(6)常见部署策略对比分析
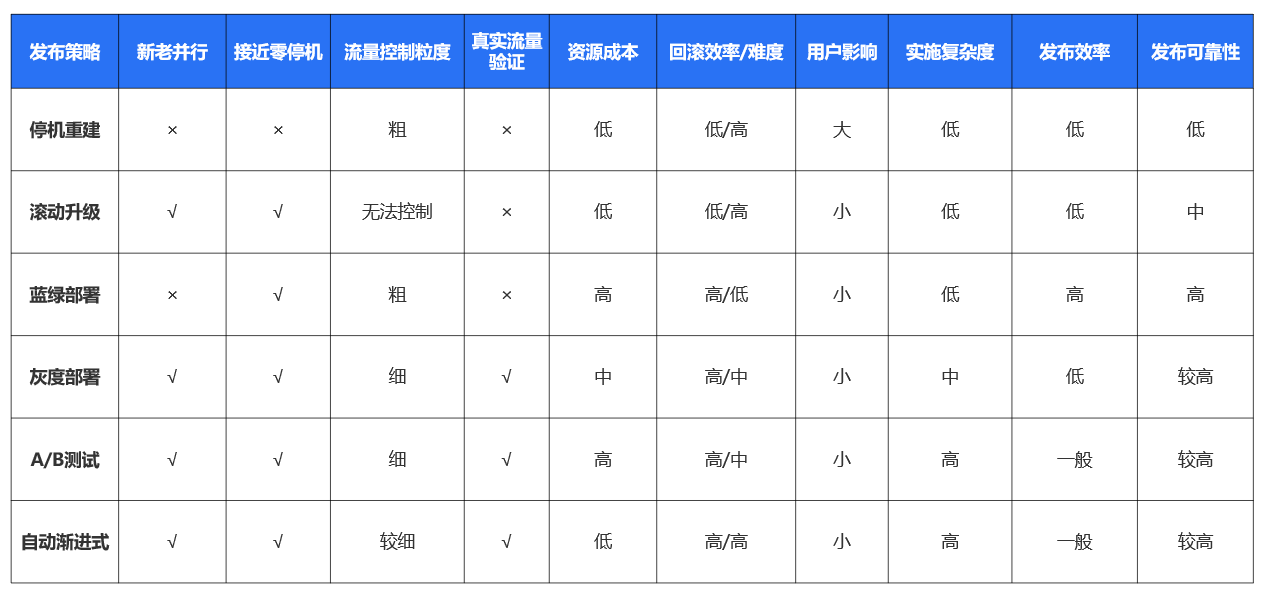
二、k8s 内置机制浅析
(1)Kubernetes
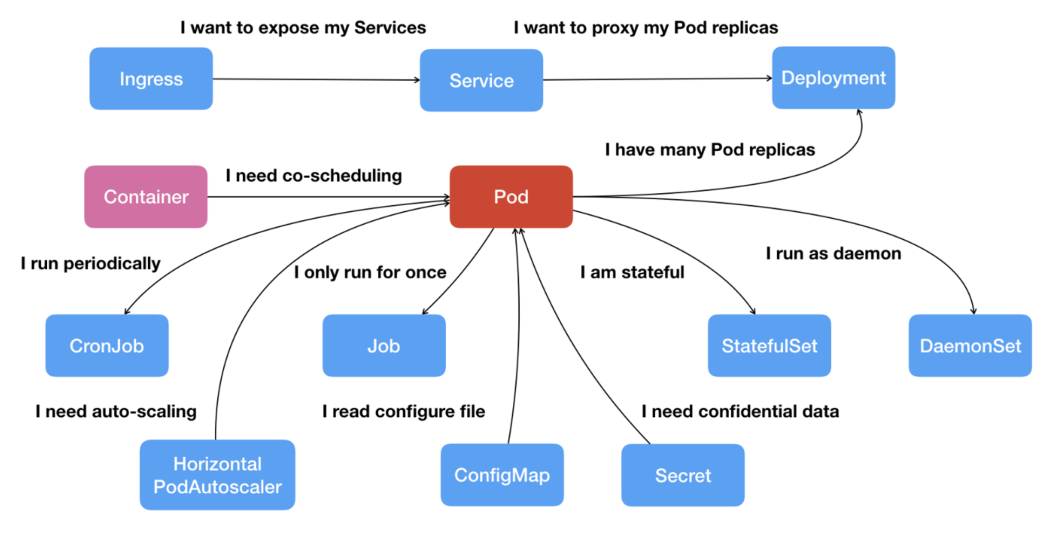
(2)K8s built-in resources for routing traffic
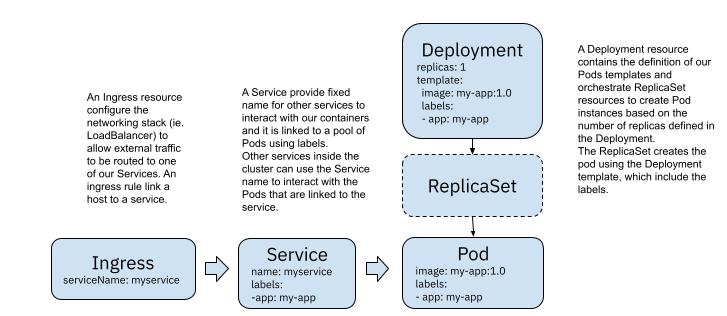
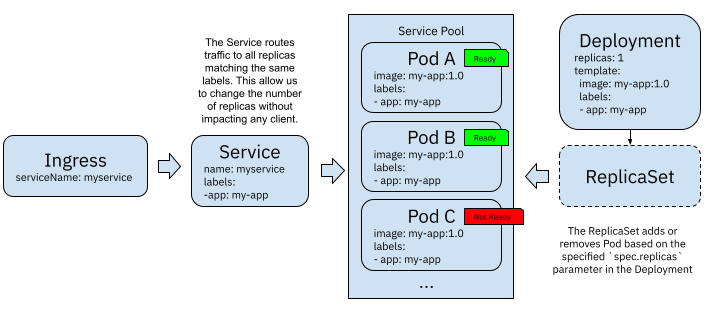
(3)K8s Service acting as a load balancer
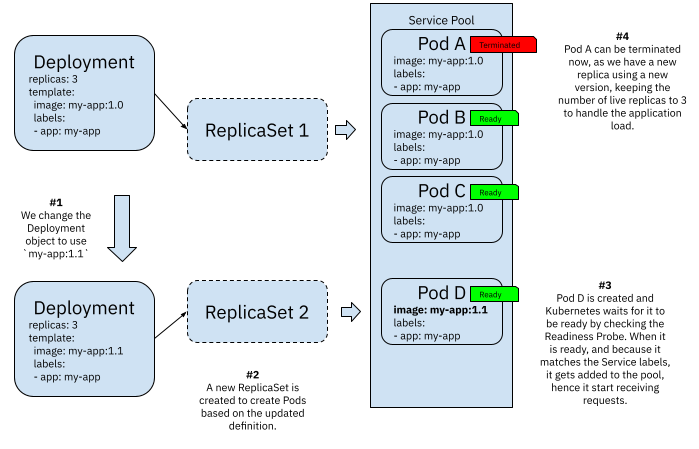
(4)Kubernetes Deployments rolling updates
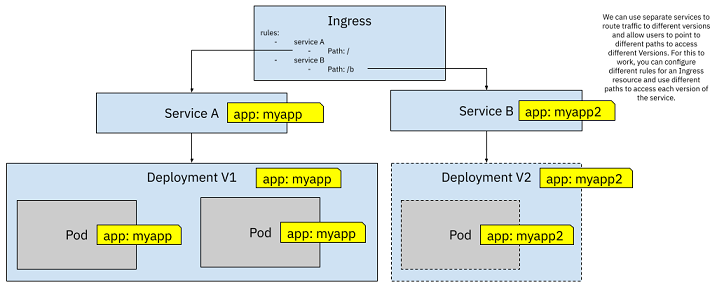
(5)Using two Ingress rules for pointing to A and B versions
三、使用CODING实施渐进式交付
(1)渐进式交付解决方案
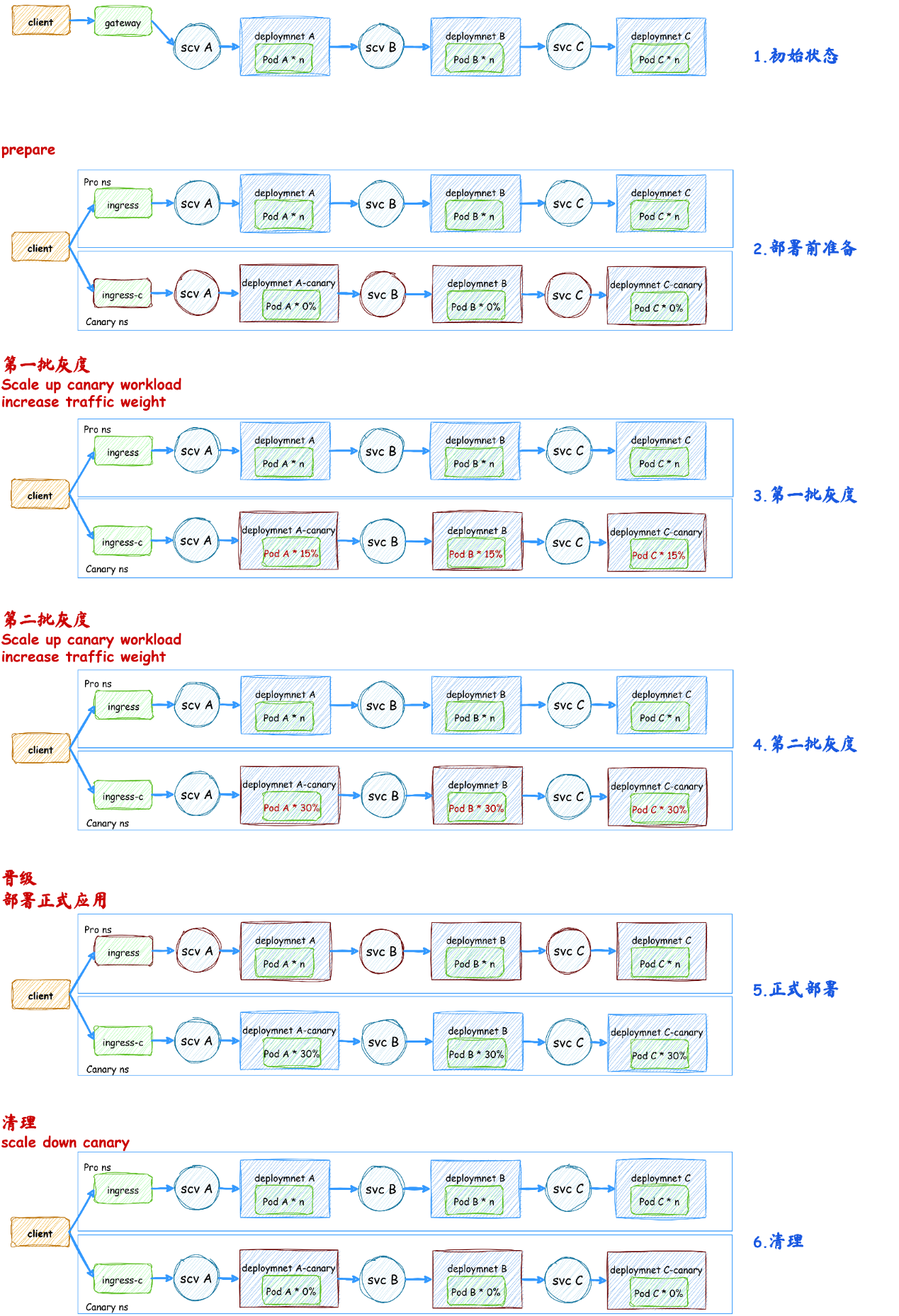
(2)参考优秀开源方案实现自研应用发布引擎——CODING Orbit
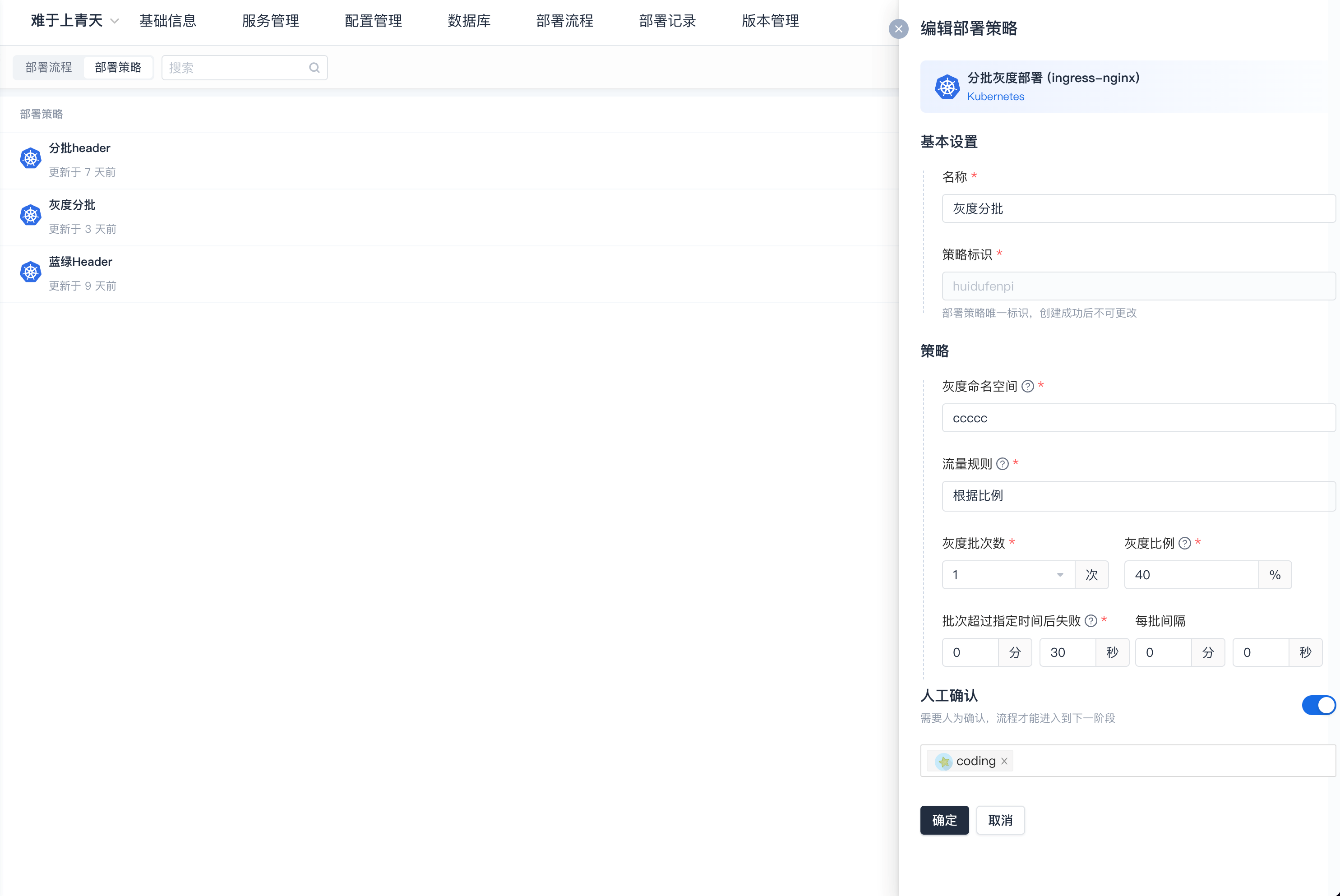
1、支持分批蓝绿、分批灰度
2、部署策略灵活配置
3、支持指定服务忽略灰度
(3)解决方案对比分析
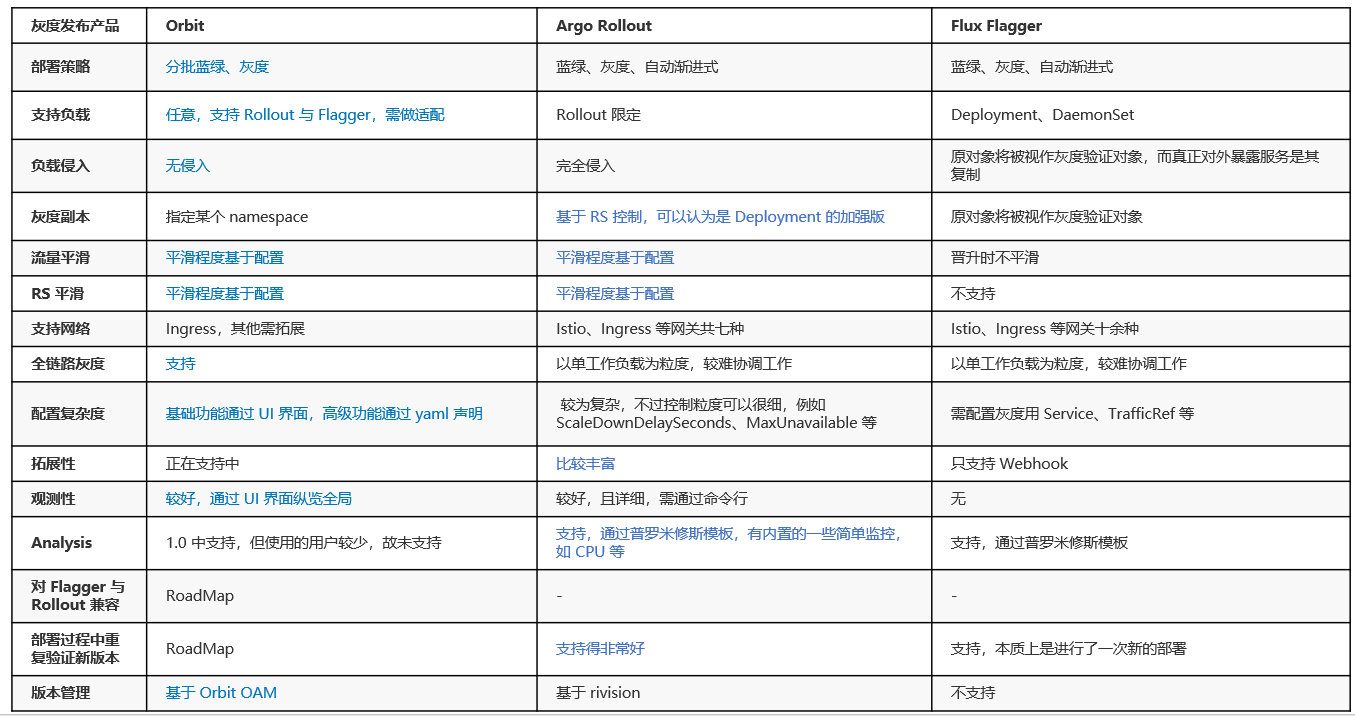
(4)GitOps 实践之渐进式交付
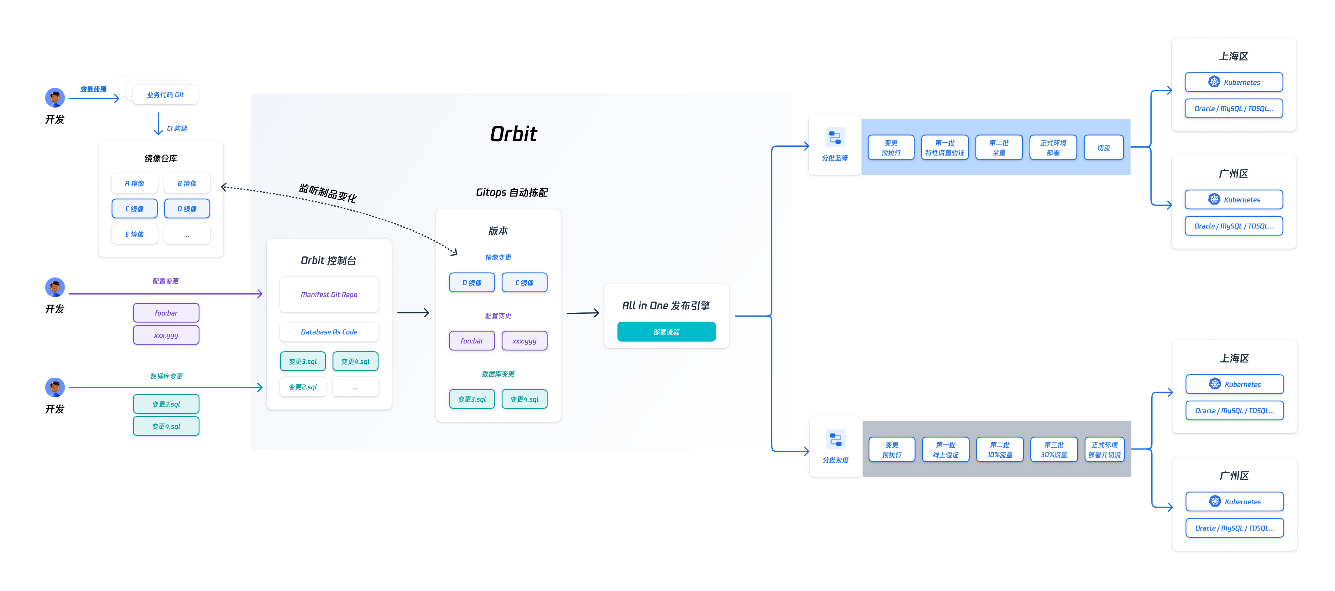
(5)面向研发的声明式应用模型
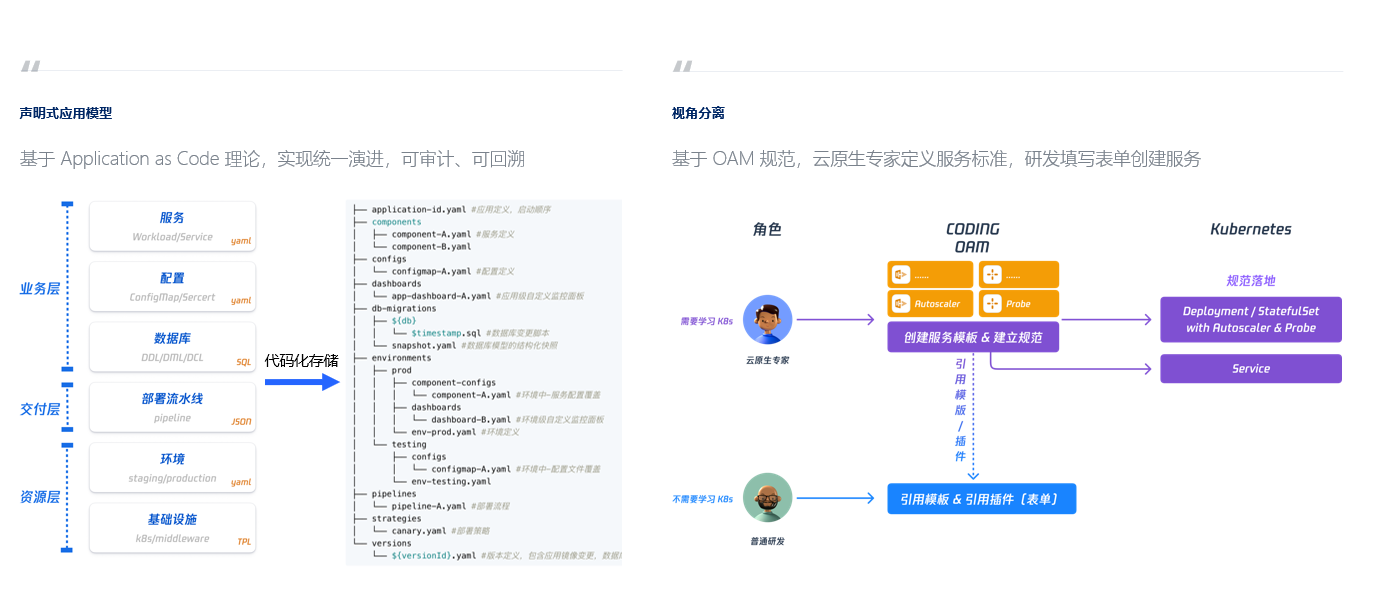
(6)应用变更自动拣配 All in One 版本化发布
(7)以应用为中心的混合云统一观测平面
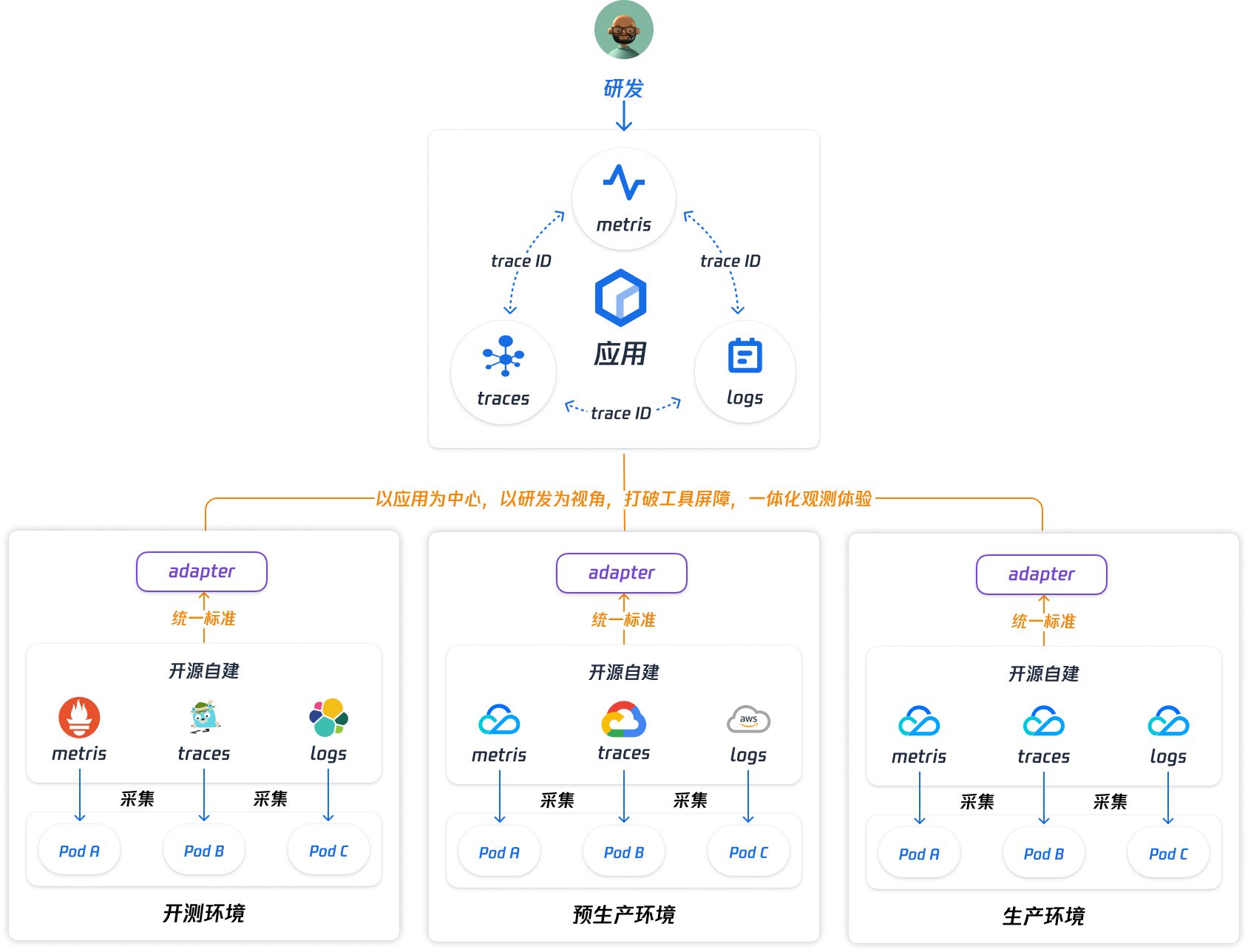
(8)以应用为中心的混合云统一观测平面
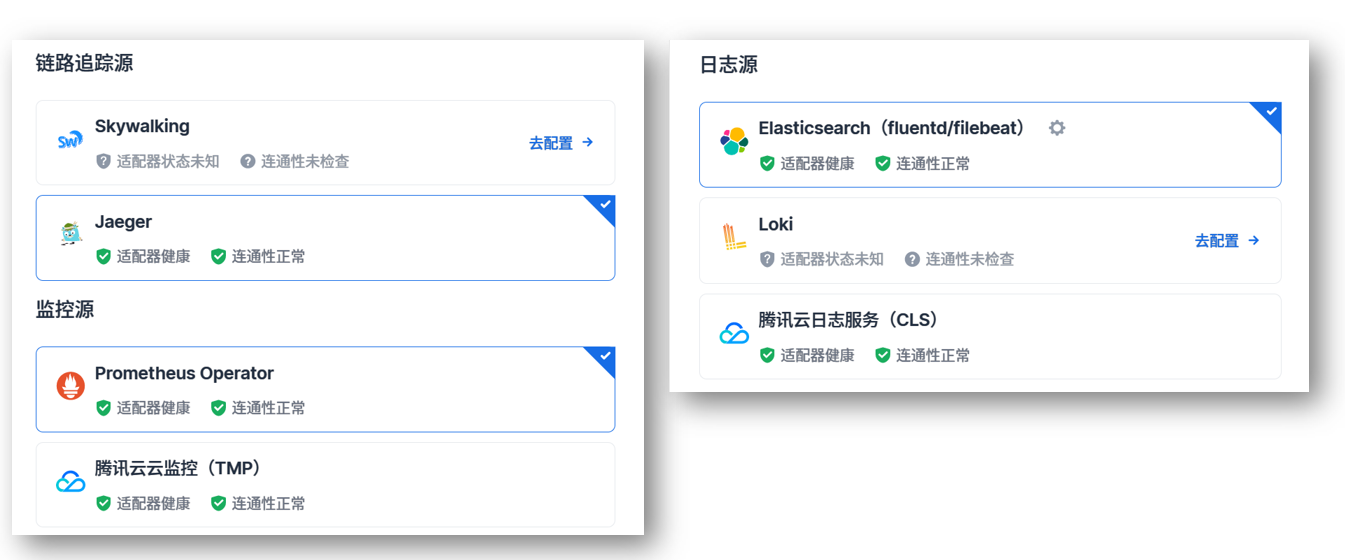
四、互动答疑(Q& A)
陈钧桐

解决方案架构师,CSM 教练,目前任职于腾讯云 CODING
从事多年技术布道工作,对于云原生时代下企业数字化转型、IT 与 DevOps 建设、价值流体系搭建等有丰富的经验,曾为多家大型企业提供咨询、解决方案以及内训服务。既关注工程师视角的云原生开发建设与最佳实践落地,也关注管理者视角的过程管理与研发效能提升。
Q1: GitOps是不是就只是用K8S实现category 灰度发布的功能?
A1:GitOps不仅仅是用K8S实现灰度发布的功能,它是一种理念,基于几个核心原则,只要你的实践符合这些原则,那么它都可以被视为GitOps的一种实现。这里的'之'字,暗示了GitOps实践的多样性,它的应用方向有很多,比如版本控制、环境管理、审计和合规性等等。今天,我们主要讨论的是如何通过GitOps渐进地交付服务,即将服务部署上线并交付给用户的过程。
在这个过程中,有许多问题需要解决,其中就包括如何根据你的需求和业务属性来选择和实施不同的策略。值得注意的是,这些策略在云原生技术出现之前就已经存在,比如在早期的服务器、单体应用等环境中,只是那时的技术环境可能是大型的物理机或传统的虚拟机,而不是现在的K8S集群。
到了云原生的时代,Kubernetes在设计时就融入了这些策略。我们之前讨论的滚动更新就是一个例子,Kubernetes已经内置了这种更新策略。但是,内置的策略肯定有一些局限性,我们可以通过其他工具在这些策略上叠加更多的功能,来处理更复杂的场景。
有些场景相对简单,使用Kubernetes内置的策略就可以很好地实现需求。但对于一些更复杂的微服务场景,比如希望实现自动化的渐进式交付,可能就需要借助其他工具,与其他工具结合,才能达到预期的效果。这是一个持续发展的过程,不同的理念将在发展中被吸收到不同层次的产品实现中。
Q2:GitOps的核心理念是否可以归结为一切皆代码,我们的配置即代码,我们的软件即代码这些,我通过这样一种把配置或者软件代码化的方式,来进行尽可能自动化的管理?
A2: GitOps的核心理念可以归结为'一切皆代码',这里包括配置和软件。通过将配置或软件代码化,我们可以实现尽可能自动化的管理。这可以用一个公式来表达,即GitOps等于基础设施即代码(IaC)加上合并请求,再加上持续集成/持续部署(CI/CD)。
这个理念就是现在业界广泛接受的各种'即代码'的概念,例如策略即代码(Policy as Code)、基础设施即代码(Infrastructure as Code)等等。所有这些都通过Git这样的版本控制系统来实现。Git的强大之处在于它可以自动化地执行版本控制,帮助我们追踪每一个更改。
当然,我们也可以在自动化的流程中加入一些人工审核的步骤。这完全没有问题,GitOps的灵活性能满足这样的需求。但最重要的是,当你需要的时候,GitOps可以实现全程自动化,极大地提高了效率和可靠性。
Q3:YAML还是手写,这个问题解决了吗?YAML的问题好像比较难解决。
A3: 确实,YAML文件手写的问题一直存在,但已有许多工具尝试解决这个问题。它们主要是通过以下方式解决的:
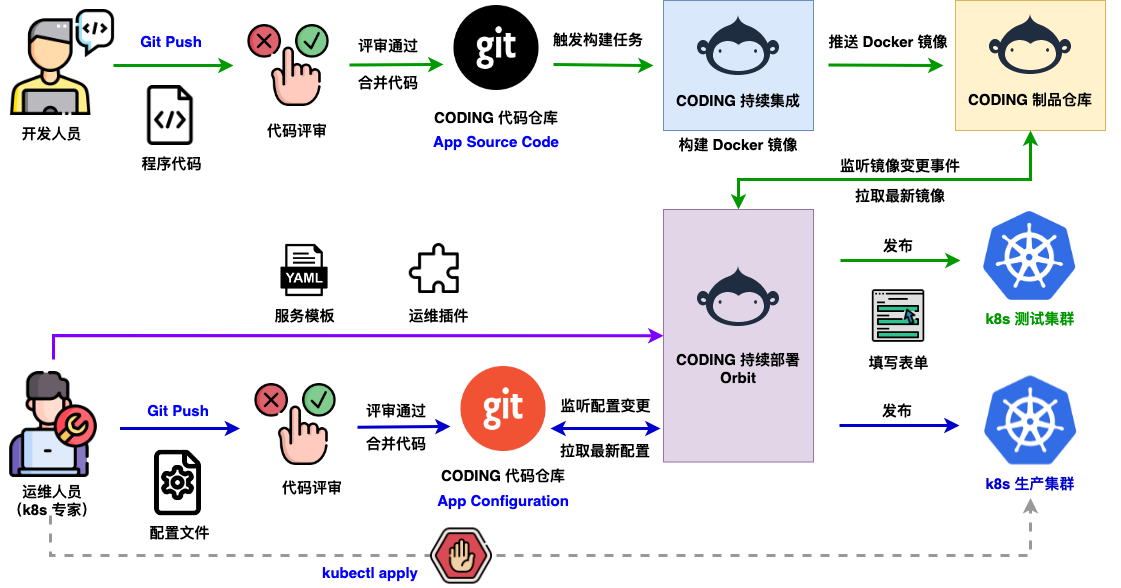
使用模板:YAML文件可以制作成模板,以便团队可以根据需要复用和自定义。这里我以CODING Orbit实现为例,它提供了运维插件和服务模板等组件。服务模板旨在解决手写YAML的问题,并简化开发人员的工作。
角色分离:通过使用模板,我们可以将运维专家和开发人员的职责分离。运维专家负责创建和维护模板,而开发人员则只需根据这些模板填写相应的参数,例如镜像地址或Replica的数量等。这样一来,开发人员无需直接编写YAML文件,从而降低了出错的风险和提高了效率。
在今天的分享中,我没有详细讲解每个工具的具体实现,因为它们在实现这些功能时的选择和方法各不相同。而且,为了避免过于像广告,我没有深入讨论具体的工具。但总体来说,这些工具致力于解决YAML手写的问题,提高开发和运维的效率。
Q4:YAML的开发是在Dev阶段,然后Gitops并不是解决开发阶段的问题,它解决的从是从代码push到Git以后整个运维的自动化,包括自动安装、自动更新、回滚等等,并且他认为这种高度标准的东西对团队的标准化要求极高,标准化不足的团队根本就玩不了,这个观点你认同吗?
A4: 这是一个非常实际且有深度的问题。在我们设计产品时,必须考虑到实际的团队环境和能力,因为我们的团队并不是万能的。
的确,GitOps主要解决的是从代码被push到仓库后的运维自动化问题,包括自动安装、自动更新、回滚等。这种高度标准化的流程确实对团队的标准化要求很高。对于某些团队来说,尤其是那些还处于标准化阶段的团队,实施这种流程可能会有挑战。
这也是为什么我们在产品设计时会考虑如何将职责分散给团队成员。比如说,我以前也是做开发的,我发现如果我需要去学习大量的运维知识和技能,那么我在业务开发上的时间就会减少。同时,云原生社区的迭代速度很快,如果一个人需要扮演多个角色,那么保持更新就会变得非常困难。因此,我们在产品设计中考虑了角色分离的策略,以便团队成员可以更专注于他们各自的角色和职责。
Q5:把部署过程固化为脚本,放到Git仓库里面,再通过CI-CD自动化运行,减少或者完全去掉手工操作,可不可以最简单去这样理解?
A5: 你的理解基本正确。我们通常把这种理念称为'应用即代码'(Application as Code)。在这个理论中,我们将整个应用分为业务层、交付层和资源层。因此,所有的内容都可以以文本的形式固定下来,然后存储在代码库中,最后通过自动化工具执行。这个过程中,我们对不同的组件进行比较,以此选择最适合我们需求的工具。请注意,这只是我们自己的工具比较,仅供参考。
实际上,我们在这里要解决的问题并不是业务编码阶段的问题,而是在你将业务代码推送到Git仓库后,从构建到部署的整个交付过程。例如,开发者只需要专注于他的业务代码的变更,然后提交到代码仓库,这将触发自动化构建,并将构建结果推送到制品库中。然后,我们可以使用一些工具,比如CODING的工具,或者其他业界的工具,将这些变更的代码组装起来,并通过发布引擎执行预定义的部署策略,最终将代码部署到不同的集群中。这大致就是实践GitOps的过程。
当然,部署并不是结束,而是开始。部署完成后,我们还需要进行后续的维护和监控,比如实现全链路的灰度发布等。这就需要结合可观测性的三大支柱,通过与观测平面的结合,集成不同的组件,以实现自动化运营,这就是我们说的持续运营。
延伸开来,我们还可以进一步进行可观测性的基础建设,然后进行集成。这样,我们就可以实现GitOps进一步的实践。
Q6:GitOps一般被认为是一切皆代码,那请问它与谷歌SRE或者我们日常的IT运维的关系是什么?
A6: 我的理解是,这些概念都是经过一定历史过程的发展,它们实际上都源自于各大公司在实践过程中的积累和总结。并不是说在某一特定时间点,突然就有了一个统一的规范或准则供所有人遵循。例如,SRE(Site Reliability Engineering)是由谷歌首先提出的,它源自谷歌内部多年的实践经验和最佳实践原则。SRE主要关注如何实施最佳实践,并且这些实践都是基于一些基础原则的。因此,SRE更注重实践层面,并会设置一些具体的指标,例如服务水平目标(SLO)。
另一方面,各种“Ops”(如DevOps、GitOps等)更像是一种文化理念,它们并没有一个严格的定义。你的行为和实践可以被视为这些理念的具体实现。例如,如果你将所有内容都存储在代码库中,并使用Git进行版本控制,那么你就可以说你正在实践GitOps理念。同样,如果你的行为促进了开发团队和运维团队的融合,那么你所做的就可以被视为是实践DevOps理念。因此,这些概念触及的层级和维度是有所不同的。
Q7:GitOps目前是否为市场刚需?它跟企业的降本增效有什么样的关系?有什么具体的产品或者说类似的成熟技术可以推荐吗?
A7: 是否采用GitOps实践,关键取决于它是否能够匹配你的业务场景和项目需求。虽然GitOps理念听起来非常理想,但实施这种理念可能需要较高的技术水平,因此需要评估实施GitOps所需的成本投入与回报。如果你的业务相对简单,团队管理不复杂,那么你可能并不需要采用GitOps。你应根据自己的业务需求和成本效益分析来决定是否采用GitOps。
当然,如果你发现团队中的工作重复度高,团队成员的时间并没有真正用在业务价值的提升上,而是浪费在了无尽的协调和沟通上,比如上线安排、工作冲突等,这时你可能会考虑是否可以采用自动化的方式来改进。GitOps能够将这些交流和决策落实到代码库中,作为唯一的事实依据,从而提高团队效率,减少不必要的沟通。所以,是否选择GitOps,应当根据具体的场景和实际需求来决定。
Q8:GitOps和运维自动化的关系,是否可以认为是自动化的基础平台?
A8: GitOps不仅仅是一种自动化的基础平台,更准确地说,它是一种理念或方法论。基于GitOps理念,我们可以进行各种实践,这包括工作行为习惯的改变,以及对工具层面的支持和应用。然而,最终落实到实践中,自动化流水线确实是实现GitOps的重要手段。我们可以选择市面上的各种工具,以支持GitOps理念的实践和自动化流程的实现。因此,GitOps和运维自动化的关系可以看作是包含和被包含,同时也是理念和实践的关系。
Q9:SRE相关的职场发展是否需要学习GitOps?如果我学了掌握了以后对我未来职业发展有什么帮助?
A9: 是否需要学习GitOps取决于你的个人兴趣和职业规划。每个人的工作角色有其特定的层级和分工,这就需要你去思考你是否愿意成为负责这些事情的人。虽然GitOps更多地聚焦在运维或交付领域,但并非每个人都需要深入这个领域。比如,如果你是一名业务开发人员,你的工作重点可能在短视频、区块链等业务应用的开发。如果你的兴趣更偏向于业务层面的实现,那么深入学习GitOps可能对你来说是一种心智负担,因为人的精力是有限的,我们不能将有限的时间都投入到无限的学习中。
我们的团队内部也遵循这个理念,会有明确的职责划分。分工是组织效率的体现,每个人都有自己的专长和职责。有些人对底层的运维和交付工作非常熟悉,他们愿意投入时间去研究这些平台的使用和配置,并将复杂的底层工作以更易用的形式提供给业务开发团队。然而,这样的人在团队中的比例始终是较小的。
总的来说,一个应用的业务价值并不完全取决于其交付的效率和质量。一个业务应用能创造高额的利润并不意味着它的交付一定非常快速和高效。反之,如果一个业务应用能创造高额的利润,那么可能就有更多的资源去提升基础设施建设。因此,这是一个需要综合考虑的问题,不能仅从一个角度去看待。
如果你对GitOps感兴趣,并且想在你的职业生涯中进一步发展,那么学习和掌握GitOps无疑将为你的未来提供更多的可能性和机会。它可以帮助你更好地理解和应用自动化的方法,提高你的工作效率,并可能帮助你在职场上取得更好的发展。
Q10:配置和secret都可以通过GitLab来进行版本控制,但如何自动化部署,包括DDL是否要向前兼容才能蓝绿灰度等等?
A10: 自动化部署和版本控制确实都可以通过GitOps实现,但如何做到这一点在很大程度上取决于你使用的工具和具体的实现策略。例如,虽然Kubernetes原生提供了部署策略和密钥管理(如Secret),但这些内置机制可能存在局限性和不足。因此,为了满足更复杂或特殊的用户场景和业务需求,你可能需要借助第三方工具,如Sealed Secrets等,来增强和扩展这些功能。你提到的 GitLab,以及我所在团队做的产品 CODING,也是这些平台中的一种选择。
至于DDL的向前兼容性以及如何实现蓝绿部署和灰度发布,这些也都是需要考虑的问题。这些策略可以通过使用适当的工具和方法来实现,但实施这些策略可能会增加额外的成本和复杂性。具体来说,当DDL无法向前兼容时,一种可能的解决方案是使用数据库迁移工具,如Flyway或Liquibase等。这些工具可以帮助你管理数据库的改变,并确保所有的更改都是可控和可追溯的。对于Kubernetes生态,这些工具可以作为部署流程的一部分,例如可以将其作为初始化容器(init containers)在应用程序启动前运行,或者可以将其作为Kubernetes Job运行,以便在特定的时间点进行数据库迁移。另一种解决方案是使用版本化的APIs或者数据模型。这种方法可以帮助你管理数据模型的变更,同时保持与旧版本的兼容性。例如,当你需要添加新的字段或者改变字段的类型时,你可以创建一个新的API版本或者数据模型版本,而旧的版本则保持不变。这样,旧的代码可以继续使用旧的API版本或数据模型,而新的代码则可以使用新的版本。总的来说,实施GitOps是一种权衡,需要在满足业务需求、管理复杂性和控制成本之间找到平衡。在决定采用哪种策略或工具时,你应该考虑到这些因素,并根据你的具体需求和资源进行选择。
往期精彩视频回看:

