《Google SRE工作手册》第四期基于SLO的告警配置及实践分享
本期分享主题是《Google SRE工作手册》之基于SLO的告警配置及实践,本期分享内容为告警设定原则与方法,面向极端业务场景的告警配置,以及引入AI的智能化告警配置实践。
一、告警设定原则与方法
告警设定的目标:根据SLO对重要的事件做出可操作性的告警。
告警设定的依据:基于服务质量指标(SLI)和错误预算,对每一个消耗大量错误预算的事件发出重大事件的告警通知。
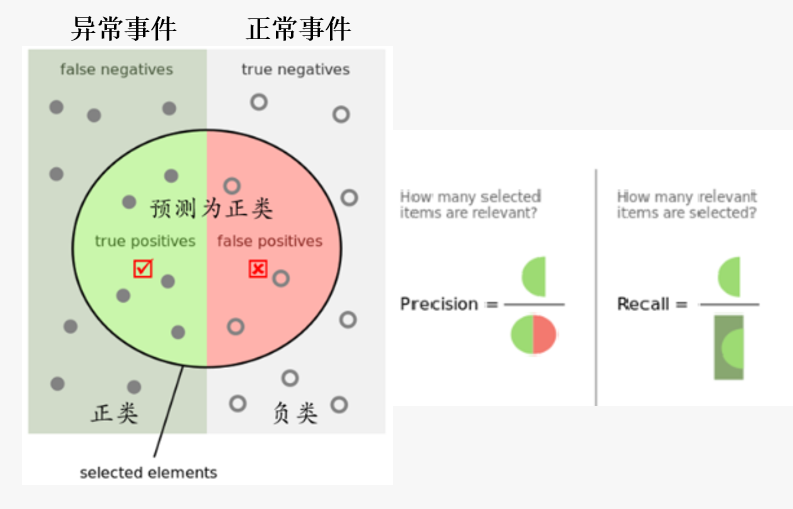
准确率(Accuracy) vs 精确率(Precision) vs 召回率(Recall)
1、准确率:所有检测正确的占总样本的比例;
2、精准率:正确检测的问题样本占总检测问题样本的比例(减少误告警);
3、召回率(查全率):正确检测的问题样本占总问题样本的比例(减少漏告警);
检测用时:检测发出告警通知需要的时间(过长影响错误预算);
重置用时:问题解决后,告警持续时间(过长增大内存和IO开销);
告警设定的方法:
目标:提高事件上报质量,尽可能兼顾精准率、查全率、检测用时、重置用时四项指标。
度量:错误预算+错误率
方法一:目标错误率≥SLO
选择一个较小的时间窗口,设置这段时间错误率超过SLO时告警。
方法二:延长告警时间窗口
方法一基础上,通过修改告警时间窗口提高精准率。
方法三:延长告警触发前的持续时间
在告警配置中,增加一个持续时间的参数;只有当检测指标在持续的一段时间里都超出阈值,才会触发告警。
方法四:根据燃烧率发出告警
引入用于缩短时间窗口的燃烧率,同时保持消耗的错误预算不变。
方法五:基于多个燃烧率的告警
告警逻辑:基于多个燃烧率监控,在燃烧率超过指定阈值时触发告警。
告警分级:按照重要性分类,如重要告警、提示告警等。
方法六:基于多个窗口、多个燃烧率的告警
对方案五持续优化,只有当预算处于活跃消耗的情况下才发出通知。
添加一个较短的时间窗口,检查在触发告警时错误预算是否仍处于消耗中。
二、面向极端业务场景的告警配置
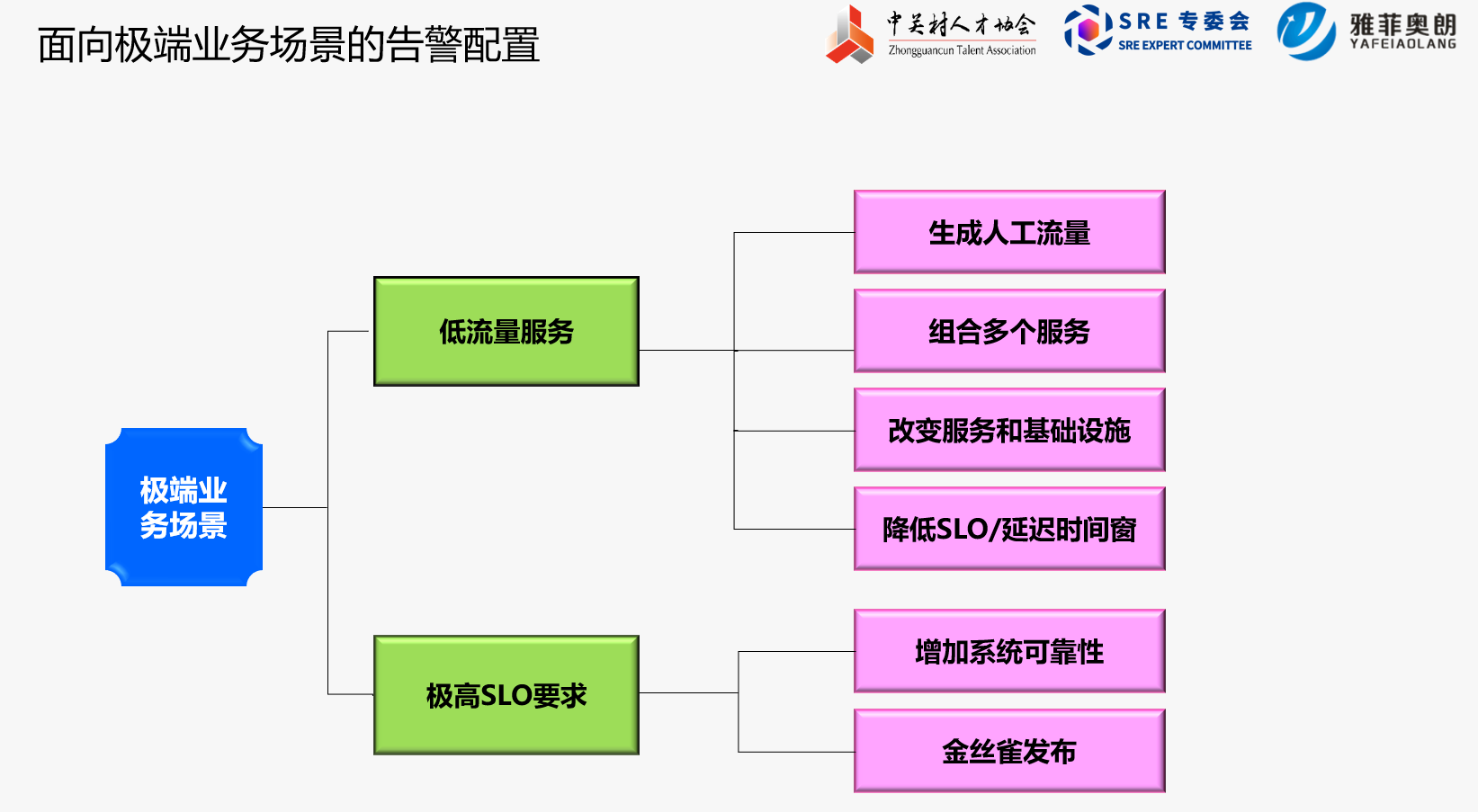
(一)低流量服务
1.1 生成人工流量
使用一个可以模拟真实用户的活动系统, 用于检查潜在的错误和高延迟请求;
监控系统检测到模拟用户活动的错误和请求,on-call工程师提前做出响应。
1.2 组合多个服务
如果多个低流量服务于一个整体的功能,可以把它们的请求组合到一个更高级别的组,精准检测、减少误报。
1.3 改变服务和基础设施
通过变更服务的方式,降低单个失败请求对用户的影响。
1.4 降低SLO/延迟时间窗
修改告警配置,设置分级阈值等。
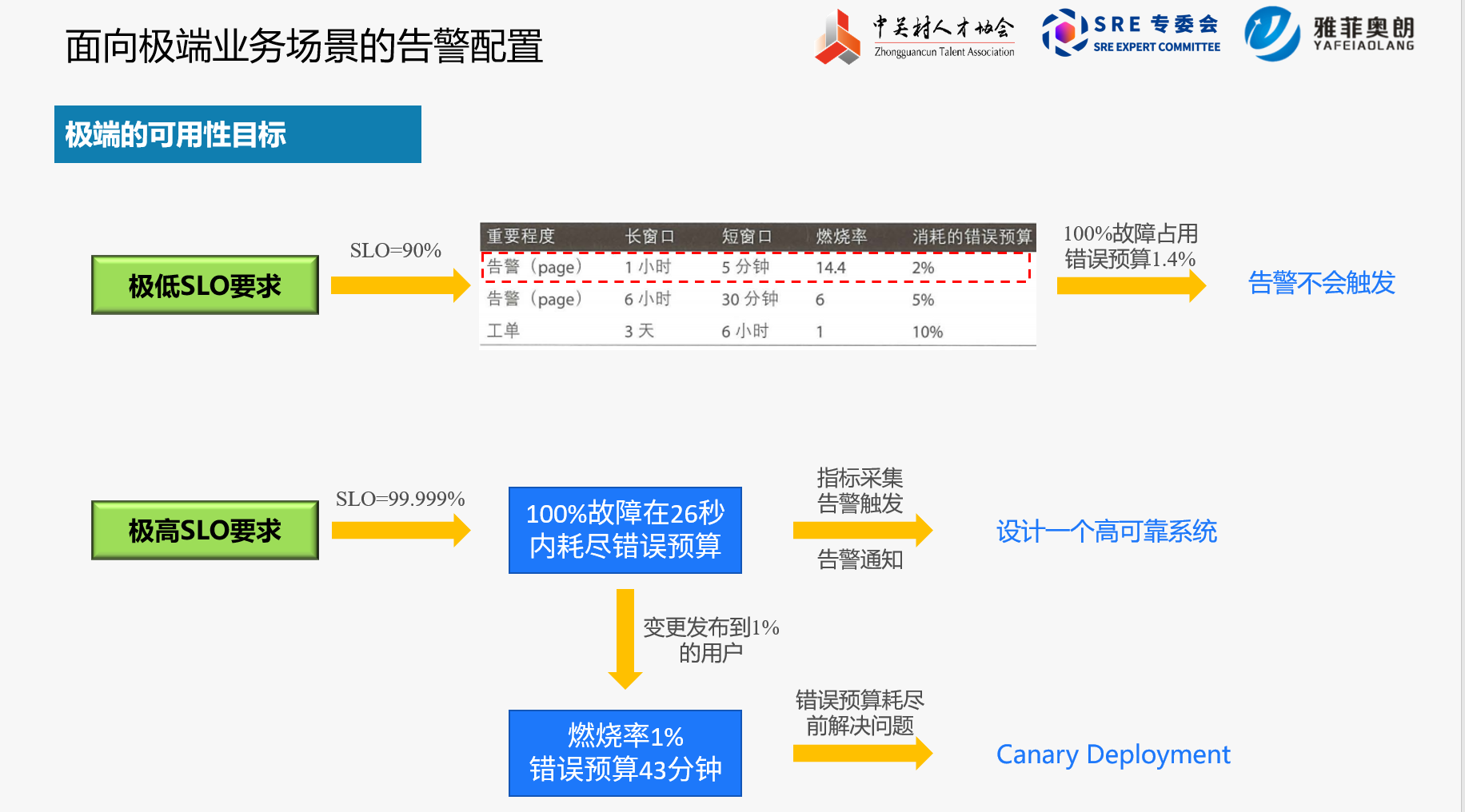
(二)极高SLO要求
2.1 增加系统可靠性
2.2 金丝雀发布
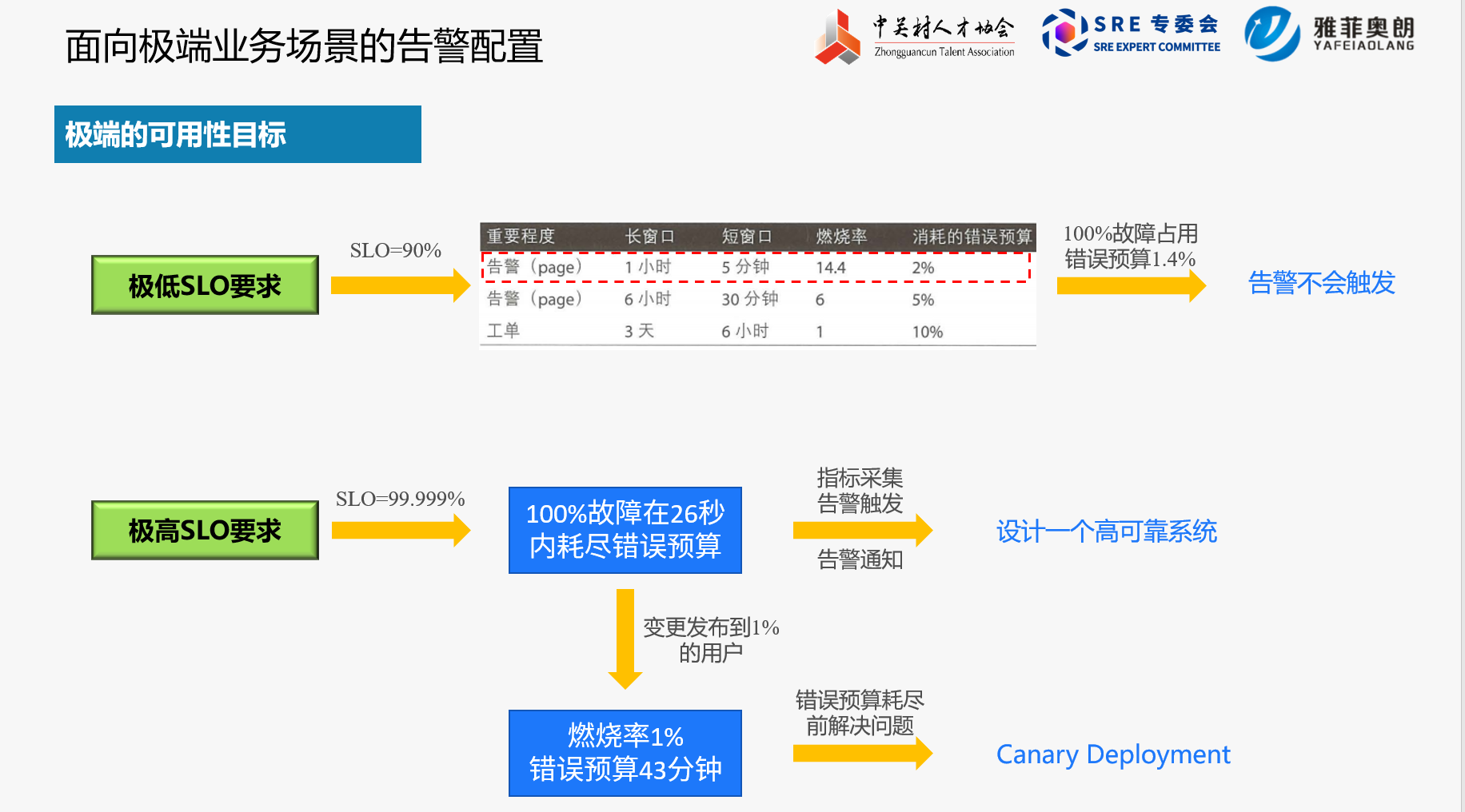
目标:扩展服务时,确保告警策略也能相应的得到扩展;避免堆积如山的琐事。
建议:不要为每个服务单独设定告警时间窗口和燃烧率参数。
按请求类型分组是管理大量 SLO 的一种技术,将可用性需求大致相似的服务分在同一组。
三、引入AI的智能化告警配置实践
随着5G/云化网络时代的来临,业务日益复杂化,指标成倍增加,无论是人员效率、技术能力、还是定位手段,都给运维带来了巨大的挑战,造成三大难题。
1、指标规模大、特征多
zabbix共监控8100多个主机,24万多个指标,指标呈现不同特征。
2、人工成本高
依赖专家经验人工设定阈值,费时费力。
3、阈值设定效果不佳
阈值严格,导致告警“泛洪”;阈值宽泛出现漏告警。
为解决以上问题,满足网络数智化演进的发展需求,项目以SRE为基础,应用AIOps技术,搭建iKPI智能异常检测系统,对各项指标进行异常点的检测,为告警、故障等处理提供自动驾驶网络感知、分析手段。
节省人工成本:
智能AI模型,实现设备指标智能异常检测
提高阈值设定效果:
首创三大类80种场景分类阈值设定算法
采用微服务架构,以快速构建新的应用。整体遵循分层解耦的原则,从下至上分为数据采集层、数据共享层、数据处理层和应用层。各层之间分工协作,边界明确。各个服务容器化,实现灵活升级,便捷扩展,支持原子能力开放。其中AI服务是核心部分。
AI服务主要分为指标分类模块和阈值检测模块。将各类指标智能聚类为三大类80种场景:时间周期类、CPU内存磁盘类、平稳突变类。
iKPI智能异常检测系统目前覆盖浙江移动语音、数据、行业视频业务等共23000多类常用指标,可进行短信告警,并将训练服务和评估服务分别对外提供API,实现原子能力开放,助力icut智慧割接平台与局数据组的指标监控智能化。
本期问题合集:
1.浙江移动的告警管理是否实现自动化或者智能化了?目前进展如何?
2.极端业务场景和自动化什么关系,智能化需求是否是刚需?
3.您的岗位“SRE研发负责人”是什么意思?到底是负责研发还是运维?
4.浙江移动SRE团队规模如何?使用的主要技术栈?
5.如何理解开源软件或开源组件,在浙江移动SRE实践中的作用?
本期视频回看:

